
Paper Reading 1 :transformer In CV
views
| comments
1.VIT#
Arxiv ID
2010.11929
幻觉翻译
2010.11929
ViT将图像划分为固定大小的patches,把每个patch当成token来处理,类似于NLP中的词嵌入。ViT使用Transformer架构,仅使用transformer的编码器,使用多头自注意力机制
推荐指数:
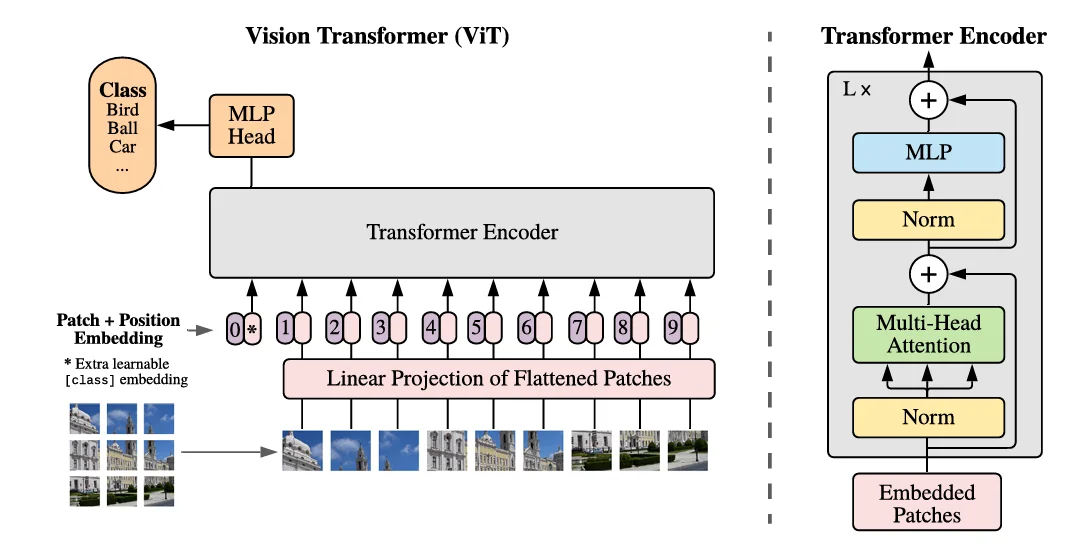
vit的基本流程:
-
图像被划分为16x16的patches,每个patch被展平并映射到一个固定维度的向量空间,即每个patch对应一个patch embedding。(这一映射过程通过可训练的线性投影(trainable linear projection)实现),然后加上一个分类令牌(class token),用于最终的分类任务。
-
然后进行位置编码(Position Encoding),vit中的位置编码是通过可学习的位置嵌入实现的。先初始化一个与patch数量相同的可学习位置嵌入矩阵。
-
位置编码被添加到patch embeddings中,以保留空间信息。
-
这些patch embeddings被输入到标准的Transformer编码器中进行处理。
-
最终的分类是通过在Transformer输出上添加一个MLP分类头来实现的。
ViT 输入输出尺寸(ViT-Base/16)
原始图像(224×224×3)→ Patches(196×768)→ Patch Embeddings(196×768)→ 加分类令牌(197×768)→ 加位置嵌入(197×768)→ 编码器输出(197×768)→ 全局表示(1×768)→ 分类结果(1×1000)
2.Swin Transformer#
Arxiv ID
2103.14030
幻觉翻译
2103.14030
Swin Transformer 引入了层次化的结构和滑动窗口机制,有效地捕捉了图像的局部和全局特征,提升了计算效率和性能,广泛应用于各种计算机视觉任务。
推荐指数: