
4.MoE架构#
Mixture of Experts(MoE)是一种通过引入多个专家模型来提升模型容量和性能的架构。MoE模型通常包含一个路由器(Router)和多个专家(Experts)。这里的多个专家可以认为是FFN层的集合,每个专家都是一个独立的神经网络模块。路由器根据输入数据的特征动态选择最合适的专家进行处理。
4.1Router机制#
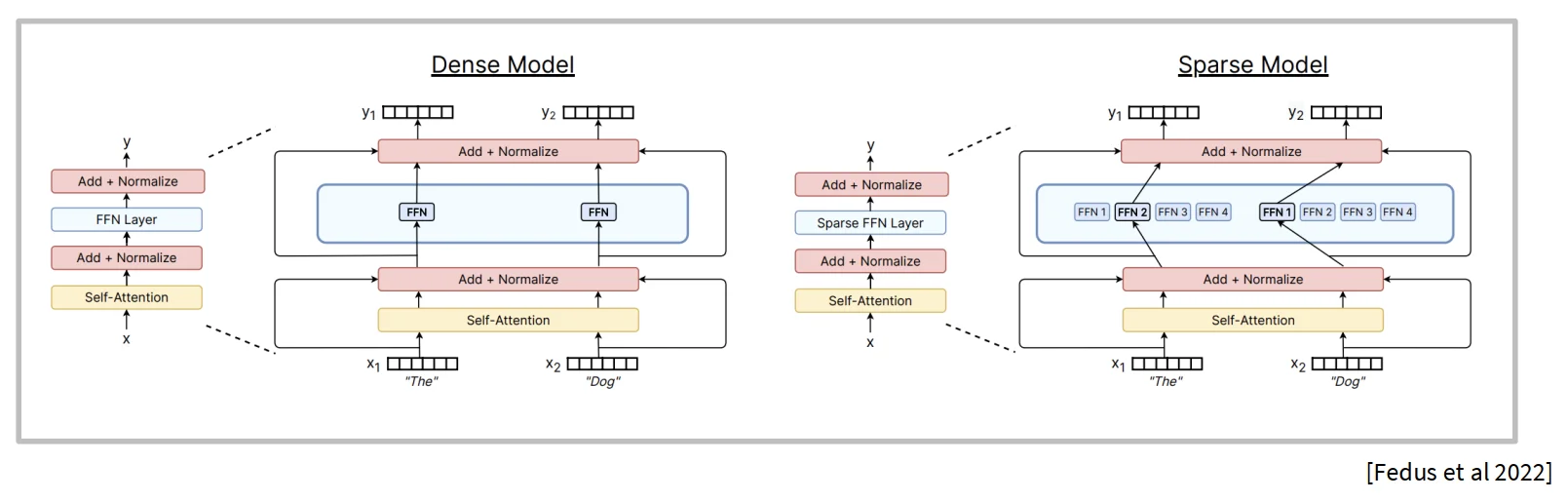
路由器的主要任务是根据输入数据的特征动态选择最合适的专家进行处理。路由器通常使用一个轻量级的神经网络来计算每个专家的权重分布,然后根据这些权重选择最合适的专家。常见的路由策略包括Top-K选择、强化学习等。
在Top-K选择中,常见的有三种方式:Token chooses experts、Expert chooses tokens、全局选择。现在大部分模型都采用Token chooses experts的方式,即每个输入token独立选择Top-K个专家进行处理。
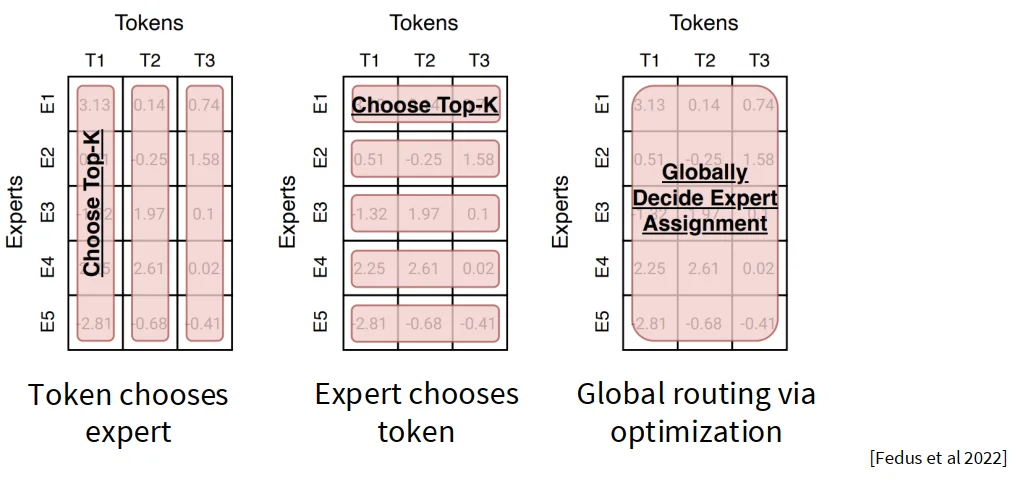
4.2 shared expert#
DeepSeek V3 证明了参数量少,数量更多的专家模型+一个共享的专家模型是非常有效的,能在多个Benchmark 的表现变得更好。
4.3 如何训练MoE模型#
如何训练MoE模型是一个关键问题。我们不能够简单地将所有专家都训练一遍,因为这样会导致计算资源的浪费。然后就是对于Router的训练,这个是不可微分的。
目前常用的训练方法包括以下几种:使用RL进行训练,随机扰动,启发式平衡损失(Heuristic balencing loss)
4.4 MoE总结#
- MoE利用了稀疏性特征,不是每个专家都参与计算,从而节省了计算资源。
- 离散路由使得选择专家的过程不可微分,但是在实践中Top-K选择已经被证明是有效的。
- MoE是有效且性价比高的,现在许多顶级模型基本都采用这种架构。
5.GPU#
5.1 学习GPU#
CPU与GPU的设计目标的区别,CPU优化的是latency(每个线程都要尽快完成任务,这个在操作系统中详细讲过各种调度算法等等知识),而GPU优化的是throughput(总的处理的数据量要大)。GPU的设计是高并行度,适合处理大量相似的计算任务,比如图形渲染和深度学习中的矩阵运算。
架构组成
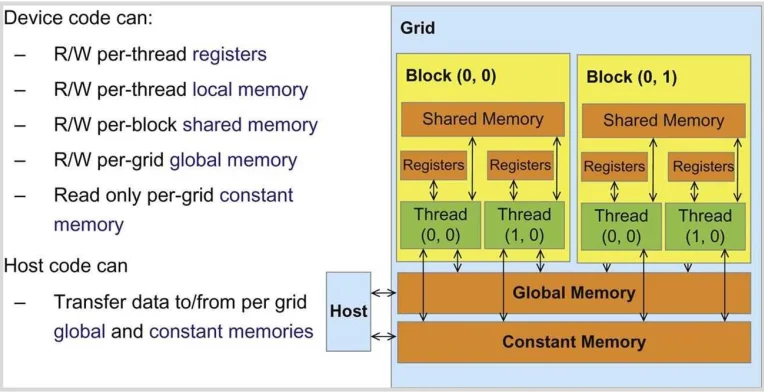
- execution units:GPU的核心计算单元,负责执行各种计算任务。一个GPU包含多个SM(Streaming Multiprocessors),每个SM包含多个SP(Streaming Processors),这些SP就是执行单元,这些可以并行处理大量的线程,进行并行运算。
- memory:GPU的内存层次结构,L1 Cache、共享内存位于SM内部,L2 Cache位于GPU芯片上,显存(VRAM)位于GPU外部。存取速度与CPU的内存层次结构类似,距离SM越近的内存层次,存取速度越快。
执行
在GPU中,执行的时候有三个重要的概念:
- thread:线程以并行方式运行,所有线程执行相同的指令,但是处理不同的数据。(单指令多线程,SIMT)
- warp:warp是GPU中线程的基本调度单位,通常一个warp包含32个线程,这些线程同时执行相同的指令。
- block:block是线程的集合,每个block在一个SM上执行,而且拥有自己的共享内存。
在执行过程中的内存访问与传输
5.2 加速GPU的Trick#
控制差异
在GPU中,线程是以warp为单位进行调度的,每个warp的线程是运行相同指令的,如果一个warp中的线程执行不同的分支路径,就会导致控制差异(Control Divergence),不能够并行执行,从而降低并行效率。因此,在编写GPU代码时,尽量避免在同一个warp内出现分支语句。
低精度计算
在深度学习中,通常使用低精度的数据类型(如FP16、INT8)来进行计算,虽然计算的次数不变,但是在进行读写存储器时,传输的数据量减少了,提升了整体的效率。
操作融合
把多个操作融合到一个CUDA kernel中执行,减少内存读写次数,例如,把卷积操作和激活函数融合到一个kernel中执行。算子融合。
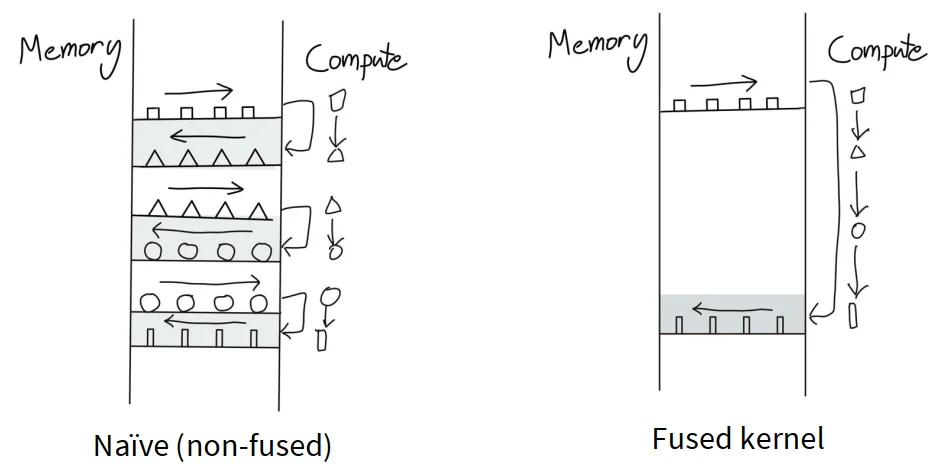 recomputation
recomputation
在训练过程中,某些中间结果可以通过重新计算得到,而不是存储在显存中。这样可以节省显存空间,允许使用更大的模型或者更大的batch size进行训练。通过在前向传播时不保存某些中间结果,在反向传播时重新计算这些结果,从而减少显存的使用。
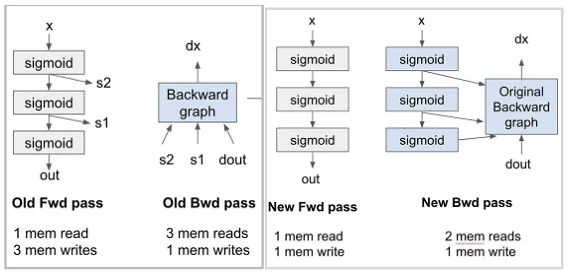 Memory coalescing and DRAM
Memory coalescing and DRAM
内存合并是指多个线程同时访问连续的内存地址,从而提高内存访问效率。DRAM的访问延迟较高,因此通过内存合并可以减少访问次数,提高整体性能。在编写GPU代码时,尽量让线程访问连续的内存地址,避免随机访问。仍然是利用了局部性原理,主要是空间局部性。实现的时候也是通过一次性传输更多数据来减少访问次数。
tiling
Tiling是一种将大规模数据划分为较小块进行处理的技术。通过将矩阵划分为块,重复读取shared memory,而不是更慢的global memory。在实现时,可以将矩阵划分为较小的子矩阵(tiles),然后在GPU上并行处理这些子矩阵。然后这里也可能出现一些问题,当矩阵的维度不是tile大小的整数倍时,可能会导致一些线程处理不完整的tile,从而影响性能。因此,在设计tile大小时,需要考虑矩阵的维度,选择合适的tile大小以最大化利用率。
5.3 Flash Attention#
Flash Attention是一种高效的注意力机制实现。Flash Attention的核心思想是将注意力计算划分为多个小块(tiles),并在GPU的共享内存中进行计算,避免了频繁访问全局内存。
对于矩阵的操作可以运用前面的,而在注意力机制里面有softmax操作,Flash Attention通过分块计算softmax。具体来说,Flash Attention在计算softmax时,将输入矩阵划分为多个小块(tiles),先在每个 tile 内计算局部中间参数(块内最大值、块内指数和),再通过跨 tile 的累积计算更新整行的全局最大值和全局指数和,最终基于全局参数完成 Softmax 的全局归一化。

6.GPU运行与CUDA kernel#
首先是一些常用运算在GPU运行时的CPU与GPU上的时间开销。
6.1 CUDA kernel#
可以自己实现CUDA kernel来加速特定的计算任务。但是一般的常用操作,pytorch等深度学习框架已经实现了高度优化的CUDA kernel,可以直接使用。(而且对于常用操作,往往自己实现的kernel不如框架自带的更快)
然后进行CUDA kernel编程的主要语言有两种CUDA C/C++、Triton。C/C++是NVIDIA官方提供的CUDA编程语言,适合底层优化。Triton语法接近Python,基于Python调用,Triton的编译器会自动生成高效的 CUDA kernel,语法简洁、开发效率高。
7.Parallelism basic#
7.1 LLM的Networking#
对于大语言模型来说,单GPU的显存以及计算速度是无法满足的,因此需要多个GPU协同。下图是多个GPU协同工作的示意图。
 collective communication
collective communication
- All-Reduce:将所有节点的数据进行归约操作(如求和、最大值等),并将结果分发给所有节点。
- Broadcast:将一个节点的数据广播到所有其他节点。
- Reduce:将所有节点的数据进行归约操作,并将结果发送到指定的节点。
- All Gather:将所有节点的数据收集到每个节点(这里并不进行归约操作)。
- Reduce Scatter:将所有节点的数据进行归约操作,并将结果分散到各个节点。
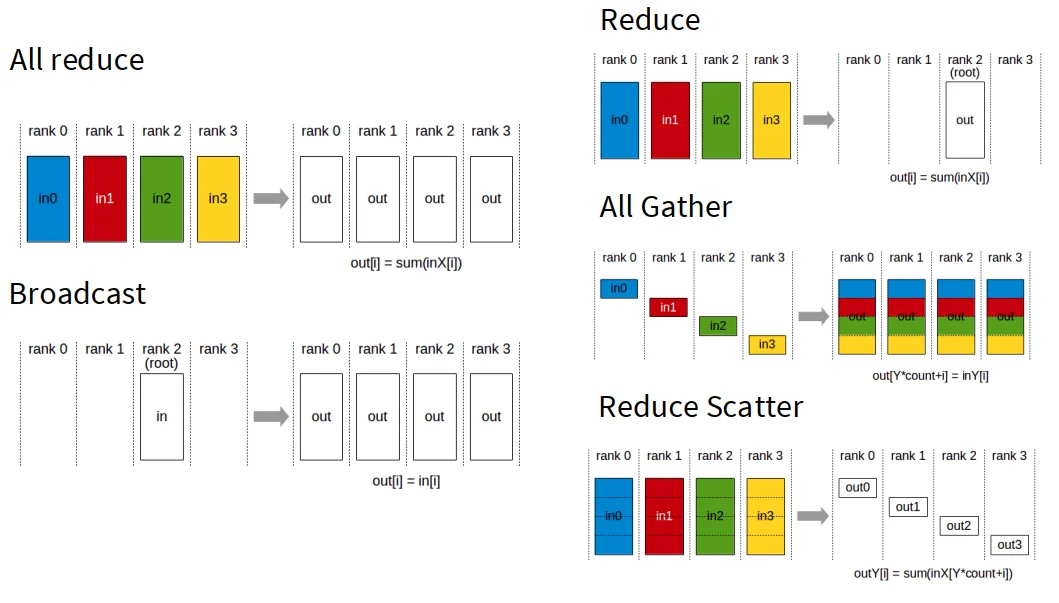 然后其中的All Reduce可以由Reduce Scatter + All Gather实现。
然后其中的All Reduce可以由Reduce Scatter + All Gather实现。
7.2 不同形式的并行#
7.2.1 Data Parallelism#
最初的数据并行是将模型复制到多个GPU上,然后将输入数据划分为B个batch,然后把这B个batch分给M个GPU进行计算,每个GPU计算完之后,对梯度进行All Reduce操作,最后更新模型参数。这样做的好处是实现简单,缺点是对与Memory非常不友好,因为每个GPU都要存一个完整的模型参数,当模型非常大时,单个GPU无法容纳整个模型。
def data_parallelism_main(rank: int, world_size: int, data: torch.Tensor, num_layers: int, num_steps: int):
for step in range(num_steps):
optimizer.zero_grad() # 清空梯度
x = data
for param in params:
x = x @ param
x = F.gelu(x)
loss = x.square().mean() # Loss function is average squared magnitude
loss.backward()
for param in params:
dist.all_reduce(tensor=param.grad, op=dist.ReduceOp.AVG, async_op=False)
optimizer.step()此处的代码就是Parallelism的简易实现, all-reduce操作的位置在计算梯度后,optimizer 更新前的,然后每个GPU计算的loss不同,梯度被 all-reduced 到不同的GPU,上面的代码中使用的是平均值(AVG),因此通过这种方式保持每个GPU的参数同步。
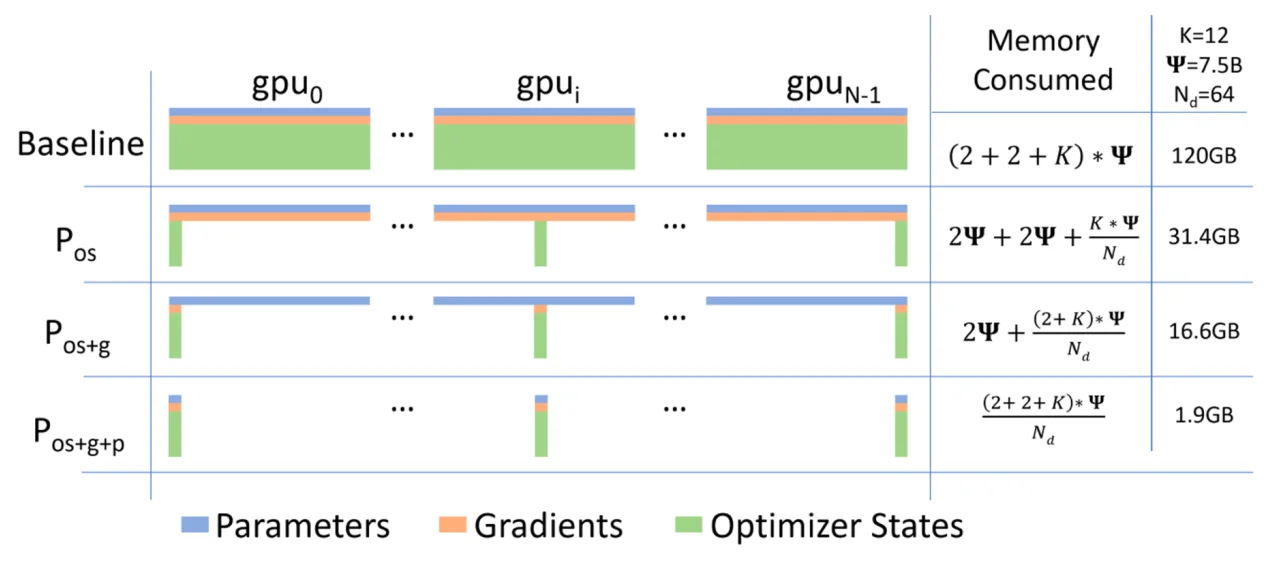
然后ZeRO提出了一种优化的数据并行方法,其有三个主要的优化阶段
- 优化器状态分区:将优化器的状态(Adam的动量等)分区到多个GPU上,每个GPU只更新自己负责的参数部分,然后通过通信进行同步。
- 梯度分区:在前面基础上,梯度也按照相同方式分区。每个GPU只保留自己负责的参数的梯度,然后All-Reduce变为Reduce-Scatter+All-Gather。
- 参数分区:在前面基础上,模型参数也进行分区,在进行前向传播/反向传播时,通过All-Gather收集参数,计算完成后再丢弃非本地部分,这样单卡的显存占用变成1/M,但是通信开销增加了。
7.2.2 Model Parallelism#
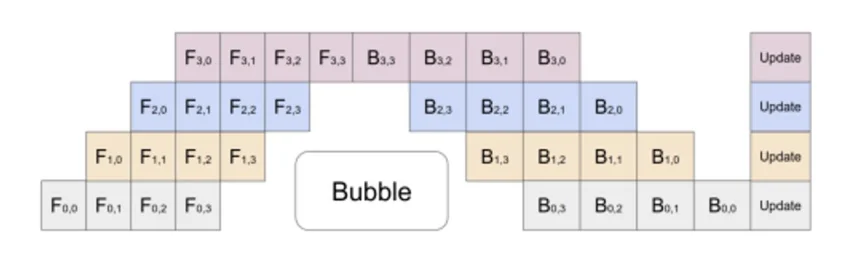
模型并行是将模型划分为多个部分,主要有两种方式:Pipeline Parallelism和Tensor Parallelism。 Poipeline Parallelism
Pipeline Parallelism是将模型划分为多个阶段,每个阶段放在不同的GPU上,像工业流水线一样进行处理。输入数据经过第一个阶段处理后,输出结果传递给下一个阶段,依次类推。
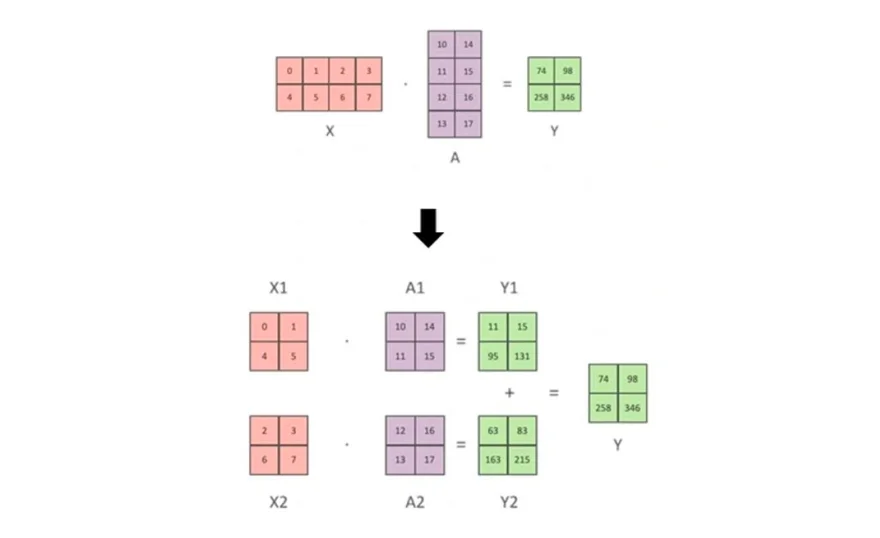
Tensor Parallelism
Tensor Parallelism是将模型的张量(如权重矩阵)划分为多个部分,分布在不同的GPU上进行计算。这种方法适用于大规模矩阵运算,避免了单个GPU的内存瓶颈。
def tensor_parallelism_main(rank: int, world_size: int, data: torch.Tensor, num_layers: int):
local_num_dim = int_divide(num_dim, world_size)
params = [get_init_params(num_dim, local_num_dim, rank) for i in range(num_layers)]
x = data
for i in range(num_layers):
x = x @ params[i]
x = F.gelu(x)
activations = [torch.empty(batch_size, local_num_dim, device=get_device(rank)) for _ in range(world_size)]
dist.all_gather(tensor_list=activations, tensor=x, async_op=False)
x = torch.cat(activations, dim=1)Tensor Parallelism是每个GPU获取部分 layer(或者子矩阵),通信时传输所有的data和 activation。
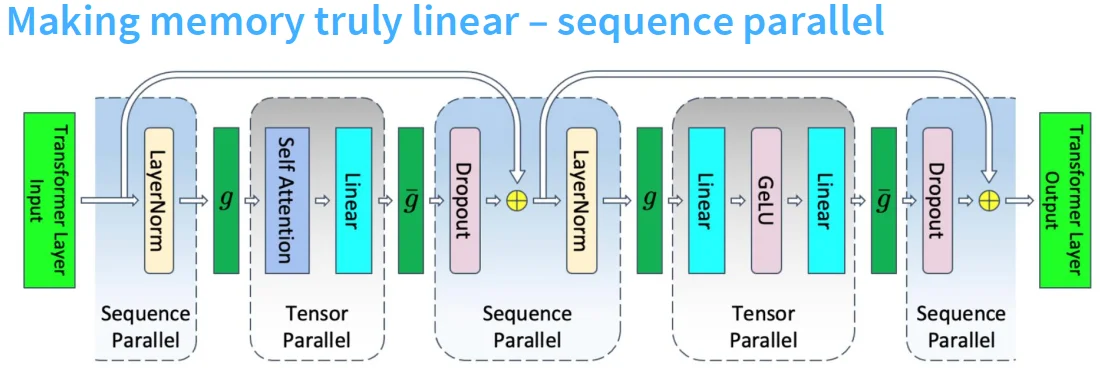
7.2.3 Sequence Parallelism#
Sequence Parallelism是针对序列数据(如文本、时间序列等)进行并行处理的方法。它将长序列划分为多个子序列,分布在不同的GPU上进行计算。每个设备处理序列的一部分。在需要全序列信息的操作(如注意力机制)时,进行通信交换信息。图中的表示All gather操作,表示Reduce scatter操作。
8.Parallelism 2#
综合到7里面了